The ALCHEmist: Automated Labeling 500x CHEaper Than LLM Data Annotators
Published:
Authors: Tzu-Heng Huang
Large pretrained models like GPT-4, Gemini, and Claude 3 are fantastic at labeling data—-whether it’s spam detection in YouTube comments or classifying topics in medical documents. But there’s a drawback: querying these models for every single data point via API calls gets expensive fast.
For instance, labeling a dataset of 7,569 points with GPT-4 could cost over $1,200. Even worse, the resulting labels are static, making them difficult to tweak or audit.
A Novel Approach to Data Labeling.
Instead of directly prompting LLMs for labels, we ask LLMs to generate programs that act as annotators. These synthesized programs encode the LLM’s labeling logic and can either label data directly or label a training dataset used to train a distilled specialist model.
Why Is This Better?
- Massive Cost Savings: Instead of making one API call per data point, we only need a handful of API calls to generate labeling programs (10 to 20 in our case). For the dataset mentioned above, the number of GPT-4 calls was reduced from 7,569 to just 10, reducing costs from $1,200 to $0.70—-a 1,700× reduction.
- Unlimited Local Predictions: Once generated, these programs can label as much data as needed without additional API costs.
- Transparency & Adaptability: The generated code is human-readable, allowing subject matter experts (SMEs) to inspect, refine, and adapt the labeling rules as needed.
Introducing Alchemist: Our Automated Labeling System.
We built Alchemist, a system that implements this approach. Empirically, Alchemist improves labeling performance on five out of eight datasets, with an average accuracy boost of 12.9%, while reducing costs by approximately 500×.
How Alchemist Works?

Step 1: Generate Labeling Programs We start with an unlabeled dataset—-such as YouTube comments or medical abstracts—-and provide an LLM with a simple prompt, instructing it to generate a labeling program that labels the data.
Step 1. Prompt the LLM for Programs We start with an unlabeled dataset (e.g., YouTube comments or medical abstracts). Write a simple prompt, an instruction, telling the LLM what you want—like a function to label spam (1) or ham (0). These prompts can integrate relevant information and may vary in their design, allowing for the synthesis of multiple programs.
Example prompt:
[Task Description] Write a bug-free Python function to label YouTube comments as spam or ham.
[Labeling Instruction] Return 1 for spam, 0 for ham, -1 if unsure.
[Function Signature] def label_spam(text_comment):
And the generated program:
def label_spam(text_comment):
"""
Classifies YouTube comments as spam (1), ham (0), or unsure (-1).
"""
if not isinstance(text_comment, str) or not text_comment.strip():
return -1
text = text_comment.lower()
# Key spam indicators
spam_phrases = ["sub4sub", "subscribe to my", "check out my channel", "follow me",
"make money", "click here", "free gift", "www.", "http", ".com"]
# Check for spam indicators
if any(phrase in text for phrase in spam_phrases):
return 1
# Check for suspicious patterns
suspicious = (
text.count('!') > 3 or
text.count('?') > 3 or
(len(text) > 10 and text.isupper()) or
any(char * 3 in text for char in "!?.,$*") or
any(segment.isdigit() and len(segment) >= 10 for segment in text.split())
)
return -1 if suspicious else 0
A single program might not capture all aspects of the labeling logic. To improve robustness, Alchemist generates multiple programs with diverse heuristics—some using keyword matching, others leveraging more complex patterns.
Step 2: Aggregate Labels with Weak Supervision The generated programs may be noisy or inconsistent. To address this, Alchemist uses weak supervision framework (such as Snorkel) to aggregate their outputs into a single, high-quality set of pseudolabels.
Step 3: Train a Local Model We can either use the pseudolabels directly or train a small, specialized model (e.g., a fine-tuned BERT model) to generalize the labeling logic. This allows completely local execution—-no further API calls required.
Handling to Complex Data Modalities.
Alchemist isn’t limited to text data. For non-text modalities like images, we introduce an intermediate step:
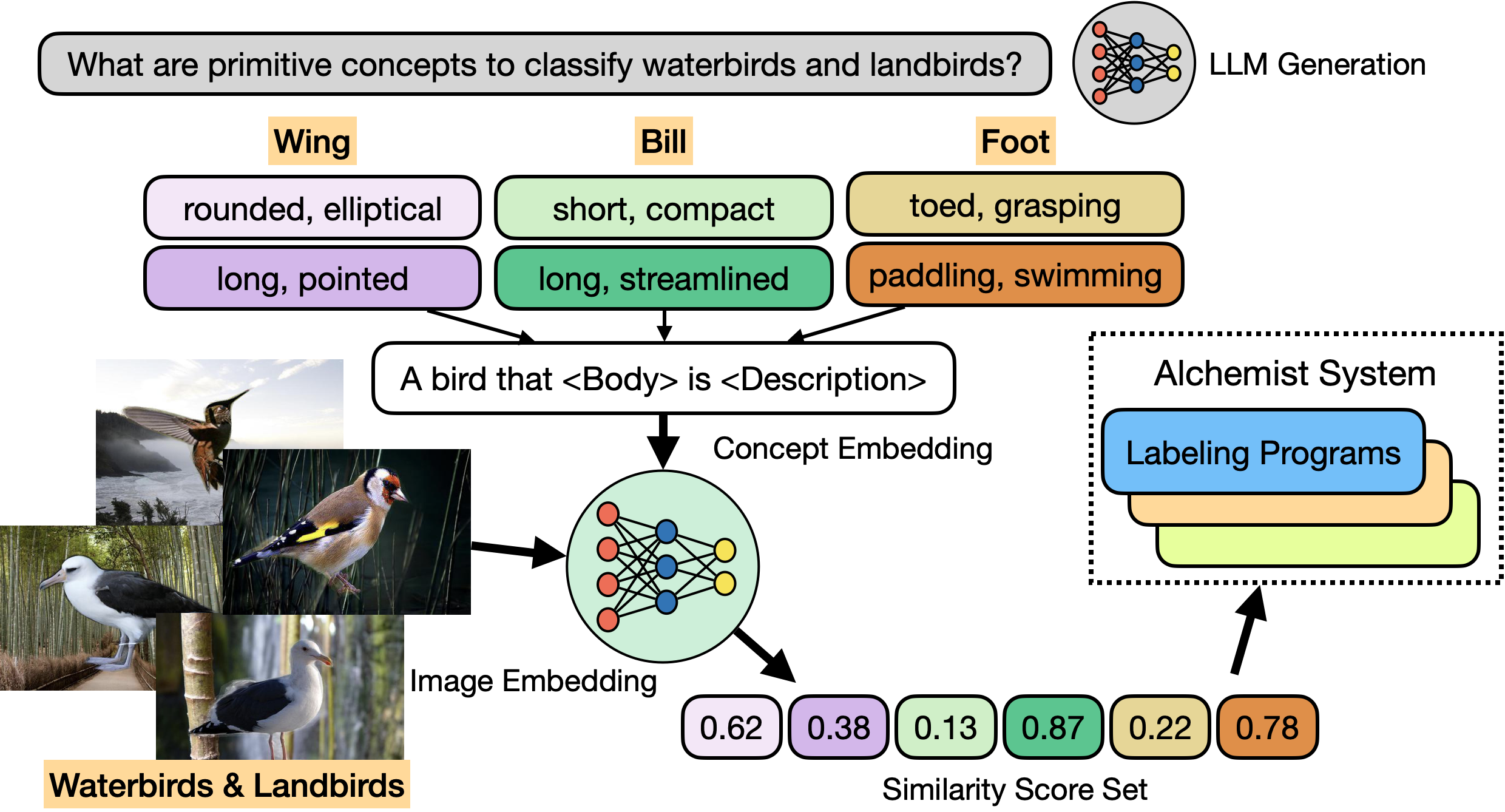
Concept Extraction: We first prompt the LLM to identify key concepts relevant to the classification task. For example, in a waterbird vs. landbird categorization task, the model may identify “wing shape,” “beak shape,” or “foot type” as distinguishing characteristics.
Feature Representation: Feature Representation: A local multimodal model (e.g., CLIP) extracts features corresponding to these concepts. This step generates low-dimensional feature vectors that can be effectively used by the labeling programs.
Program Synthesis: Using the extracted features and their similarity scores, we prompt the LLM to generate labeling programs that automate the annotation process.

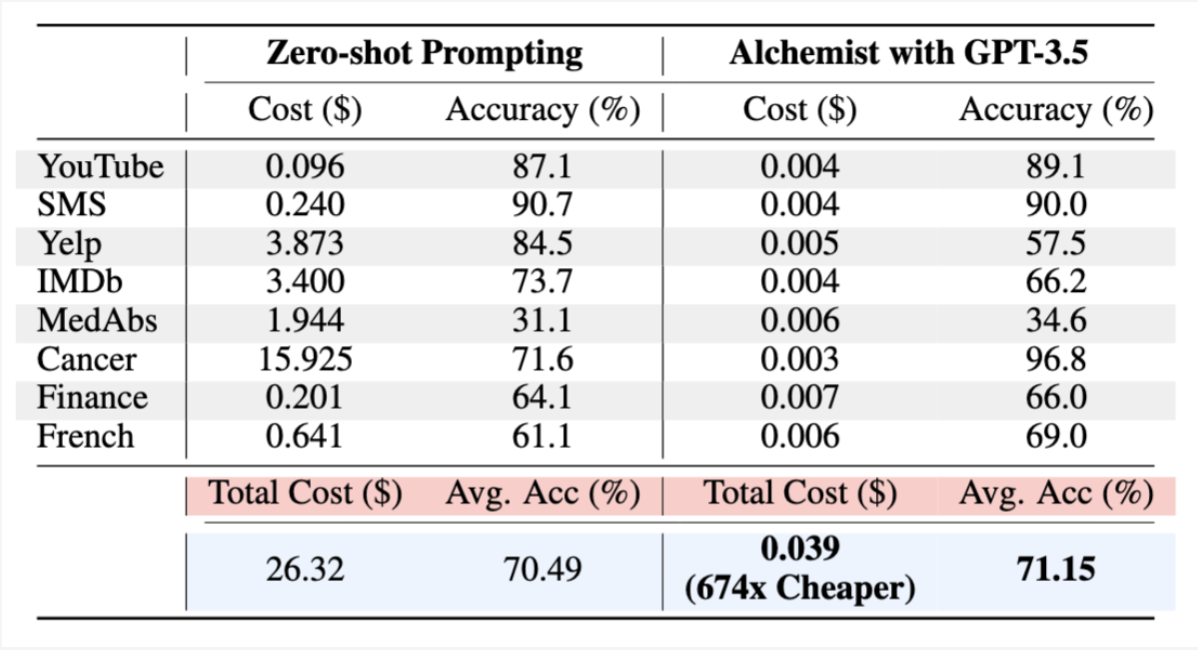
Experimental Result (1).
We use eight text domain datasets to evaluate Alchemist. We use GPT-3.5 to generate 10 labeling programs for each dataset and compare labeling performance to LLM zero-shot prompting. Here are the results.
Experimental Result (2).
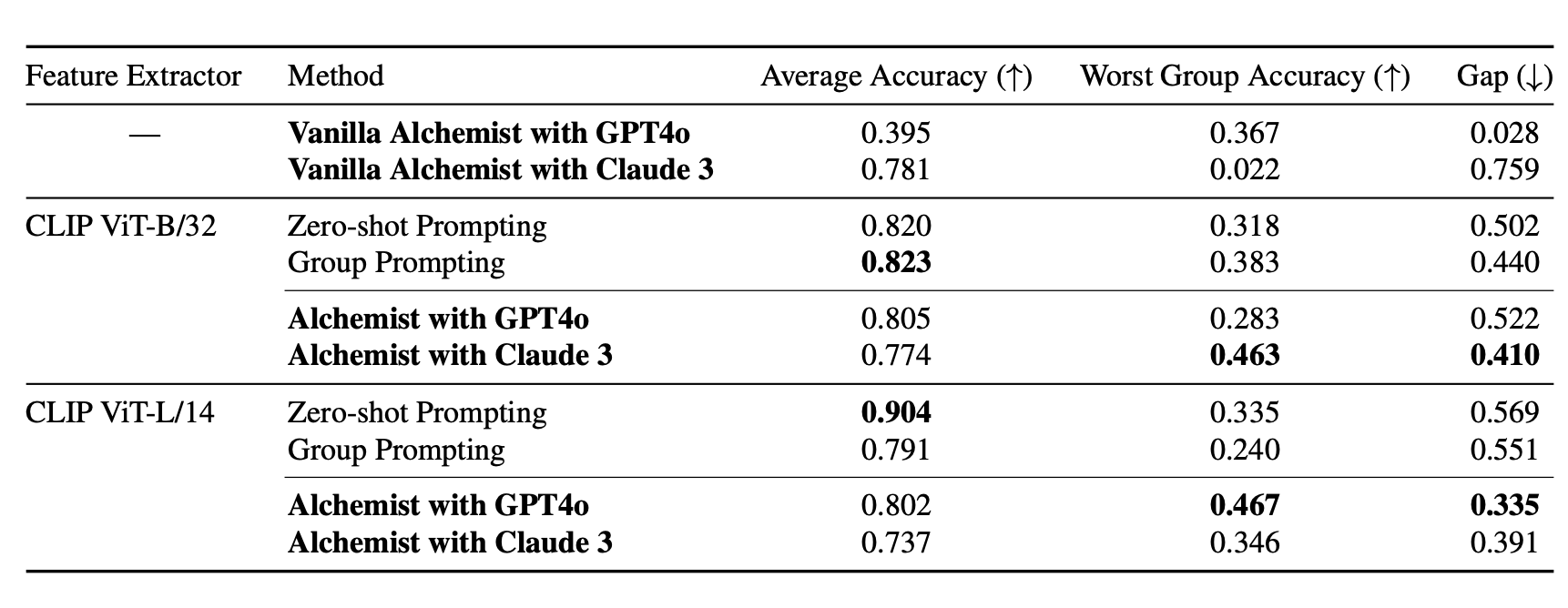
Next, we validate the extension of Alchemist to richer modalities. We extract features for the key recognized concepts by employing CLIP as our local feature extractor. Then, we converts these feature vectors to produce a set of similarity scores. Armed with these scores, we describe scores associated with their concepts in prompts and ask GPT4o and Claude 3 for 10 programs. Results show that Alchemist achieves comparable performance on average accuracy while improving robustness to spurious correlations. This is a key strength of Alchemist: targeting salient concepts to be used as features may help move models away from spurious shortcuts found in the data. This validates Alchemist’s ability to handle complex modalities while improving robustness.
Conclusion.
We propose an alternative approach to costly annotation procedures that require repeated API requests for labels. Our solution introduces a simple notion of prompting programs to serve as annotators. We developed an automated labeling system called Alchemist to embody this idea. Empirically, our results indicate that Alchemist demonstrates comparable or even superior performance compared to language model-based annotation, improving five out of eight datasets with an average enhancement of 12.9%.
🙋🏻 Still, prompting ChatGPT for your labels repeatedly? Try to generate your program code to save the project expenses!
- Full paper link: https://arxiv.org/abs/2407.11004
- Github repo: https://github.com/SprocketLab/Alchemist
- Twitter post: https://x.com/zihengh1/status/1843401287351824783