Alignment, Simplified: Steering LLMs with Self-Generated Preferences
Published:
Authors: Dyah Adila
Imagine you can steer a language model’s behavior on the fly- no extra training, no rounds of fine-tuning, just on-demand alignment. In our paper, “Alignment, Simplified: Steering LLMs with Self-Generated Preferences”, we show that this isn’t just possible—it’s practical, even in complex scenarios like pluralistic alignment and personalization.
The Traditional Alignment Bottleneck
Traditional LLM alignment requires two critical components: (1) collecting large volumes of preference data, and (2) using this data to further optimize pretrained model weights to better follow these preferences. As models continue to scale, these requirements become increasingly prohibitive—creating a bottleneck in the deployment pipeline.
This problem intensifies when facing the growing need to align LLMs to multiple, often conflicting preferences simultaneously (Sorensen et al., 2024), alongside mounting demands for rapid, fine-grained individual user preference adaptation (Salemi et al., 2023).

Our research challenges this status quo: Must we always rely on expensive data collection and lengthy training cycles to achieve effective alignment?
The evidence suggests we don’t. When time and resources are limited—making it impractical to collect large annotated datasets—traditional methods like DPO struggle significantly with few training samples. Our more cost-effective approach, however, consistently outperforms these conventional techniques across multiple benchmarks, as demonstrated below:
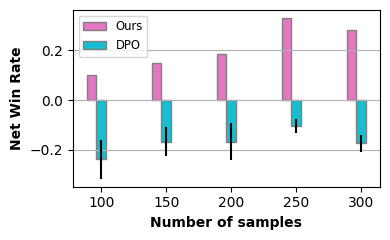
These results reveal a clear path forward: alignment doesn’t have to be a resource-intensive bottleneck in your LLM deployment pipeline. Enter AlignEZ—our novel approach that reimagines how models can adapt to preferences without the traditional overhead.
On the fly Alignment: The EZ Solution
At its core, AlignEZ enables the (non-trivial) combination of two most cost-efficient choice of data and algorithm–using self-generated preference data and cut down the compute cost by replacing fine-tuning with embedding editing. This combination is non-trivial for several reasons:
- Model generated signal is often noisier in nature, necessitating an approach that is able to effectively harness alignment signal from the noise.
- On top of assuming access to clean human-labeled data, current embedding editing approaches assumes 1-vector-fits-all for to steer the LLM embeddings. By operating in carefully identified subspaces, it enables seamless extension to multi-objective alignment scenarios.
Now that hopefully have convinced you why this is the way to go, let’s break down how AlignEZ works, in plain English:
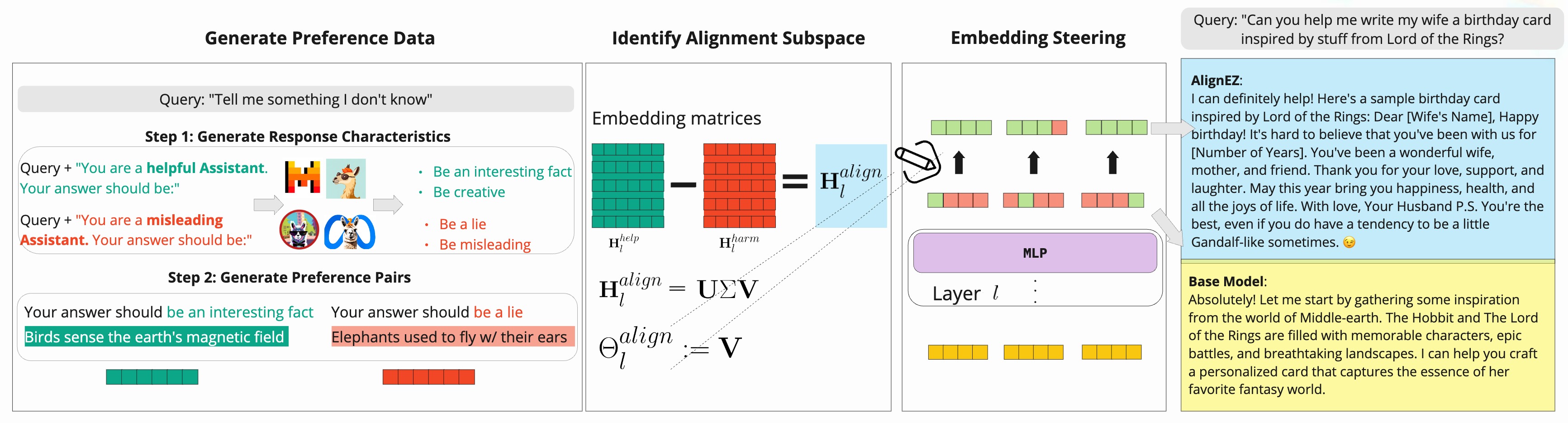
Step 1: Self-generated Preference Data
Instead of collecting human-labeled preference data, AlignEZ lets the model create its own diverse preference pairs. Diversity is key to capturing a broad range of alignment signals, ensuring we capture as much alignment signal as possible. We achieve this through a two-step prompting strategy:
- For each test query, we prompt the model to explicitly identify characteristics that distinguish “helpful” from “harmful” responses. This process is customized to the specific task at hand. For example, in a writing task, we might contrast attributes like “creative” versus “dull” to tailor the alignment signals appropriately.
- The model then generates multiple responses to the test query, each deliberately conditioned on the identified characteristics.
By applying this process across our dataset, we develop a rich preference dataset where each query is paired with multiple responses that reflect various dimensions of “helpful” and “unhelpful” behavior.
Importantly, we recognize that the initial batch of generated data may contain significant noise—often resulting from the model failing to properly follow the conditioned characteristic. As a critical first filtering step, we eliminate samples that are too similar in the embedding space, a characteristic that research by (Razin et al., 2024) has shown to increase the likelihood of dispreferred responses.
Step 2: Identify Alignment Subspace
With our self-generated preference data in hand, we next identify the alignment subspace within the LLM’s latent representation. Our approach adapts classic techniques from embedding debiasing literature (Bolukbasi et al., 2016) that were originally developed to identify subspaces representing specific word groups.
Formally, let $\Phi_l$ denote the function mapping an input sentence to the embedding space at layer $l$, and each preference pair as $(p_i^{help}, p_i^{harm})$. Firt, we construct embedding matrices for helpful and harmful preferences:
\[\begin{equation} \textbf{H}_{l}^{help} := \begin{bmatrix} \Phi_{l}(p_1^{help}) \\ \vdots \\ \Phi_{l}(p_K^{help}) \end{bmatrix}^T, \quad \textbf{H}_{l}^{harm} := \begin{bmatrix} \Phi_{l}(p_1^{harm}) \\ \vdots \\ \Phi_{l}(p_K^{harm}) \end{bmatrix}^T, \end{equation}\]where $K$ is the total number of preference pairs. Next, alignment subspace is identified by computing the difference between the helpful and harmful embeddings:
\[\begin{equation} \textbf{H}_{l}^{align} := \textbf{H}_{l}^{help} - \textbf{H}_{l}^{harm}. \end{equation}\]We then perform SVD on $\textbf{H}_{l}^{align}$:
\[\begin{equation} \textbf{H}_{l}^{align} = \textbf{U}\Sigma\textbf{V} \\ \Theta_l^{align} := \textbf{V}^T, \end{equation}\]An important trick we add here is to remove subspace directions that are already well-represented in the original LLM embedding. Formally for a query $q$:
\[\begin{equation} \Theta_{l,help}^{align}(q) := \left\{\,\theta \in \Theta_l^{align} \,\middle|\, \cos\left(\Phi_l(q),\theta\right) \leq 0 \right\}, \end{equation}\]This prevents any single direction from dominating the editing process and ensures we only add necessary new directions to the embedding space.
Step 3: Edit Embeddings During Inference
Finally, during inference when generating a new response, we modify the model’s hidden representations by projecting them in the direction of the alignment subspace $\Theta_l^{align}$. Our editing process is as follow:
\[\begin{aligned} \hat{x}_l &\leftarrow x_l,\\ \text{for each } \theta_l \in \Theta_l^{align}:\quad \hat{x}_l &\leftarrow \hat{x}_l + \alpha\,\sigma\!\bigl(\langle \hat{x}_l, \theta_l \rangle\bigr)\,\theta_l, \end{aligned}\]where $\sigma(\cdot)$ is an activation function and $\langle \cdot,\cdot \rangle$ denotes inner product. We iteratively adjust $\hat{x}_l$ by moving it toward or away from each direction $\theta_l$ in $\Theta_l$. We set $\sigma(\cdot)=\tanh(\cdot)$ with $\alpha = 1$, enabling smooth bidirectional scaling bounded by $[-1,1]$.
Why It Works: The Intuition
The core insight behind AlignEZ is that alignment information already exists within the pre-trained model - we just need to find it and amplify it.
Think of it like a radio signal. The alignment “station” is already broadcasting inside the model, but it’s mixed with static. Traditional methods try to boost the signal by retraining the entire radio (expensive!). AlignEZ instead acts like a targeted equalizer that simply turns up the volume on the channels where the alignment signal is strongest.
For more detailed explanation of our method with (more) proper mathematical notations, check out our paper!
How Does AlignEZ perform?
Our experiments reveal that AlignEZ achieves strong alignment gains with a fraction of the computational resources traditionally, significantly simplifies multi-objective/pluralistic alignment process, is compatible with and expedites more expensive alignment algorithms, and
Result 1: Boosting pre-trained Models Alignment Gain
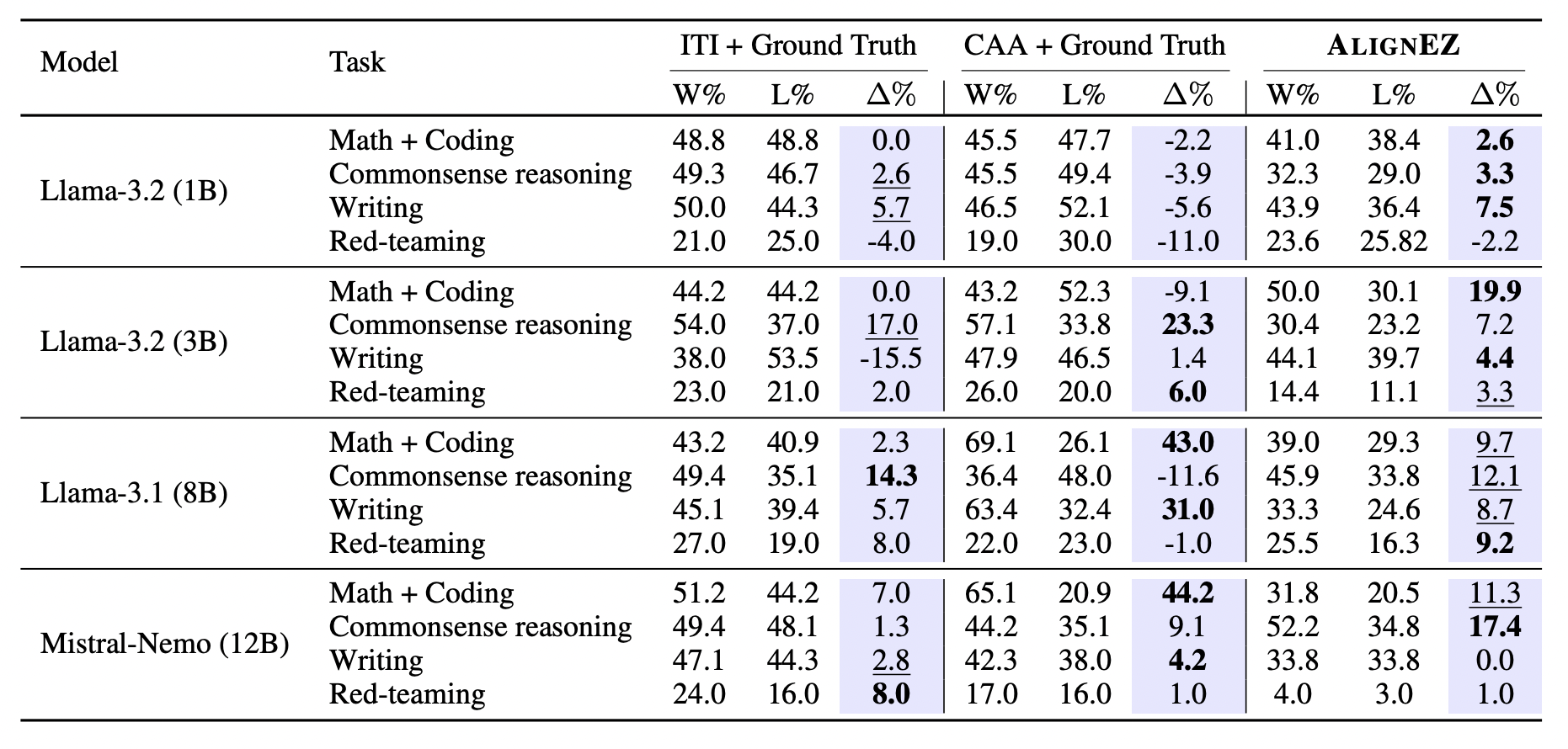
We use the standard alignment automatic evaluation, GPT as a judge evaluation (Zheng et al., 2023), and measure $\Delta\%$, defined as Win Rate (W%) subtracted by lose rate (L%) against the base models.
AlignEZ delivers consistent improvements, achieving positive gains in 87.5% of cases with an average ∆% of 7.2%– showing more reliable performance than the test-time alignment baselines 75% for ITI and 56.3% CAA. Perhaps the most significant advantage? AlignEZ accomplishes all this without requiring ground-truth preference data—a limitation of both ITI and CAA.
Result 2: Enabling Fine-Grained Multi-Objective Control
Next, we test AlignEZ’s capacity for steering LLMs to multiple preferences at once. We test for two key abilities: (1) fine-grained control across dual preference axes (demonstrating precise regulation of each axis’s influence), and (2) ability to align to 3 preferences simultaneously. Following the setup from (Yang et al., 2024), we evaluate on three preference traits: helpfulness, harmlesness, humorous.
On fine-grained control, we we modulate the steering between two preference axes by applying weight pairs ($\alpha$, 1 − $\alpha$), where $\alpha$ ranges from 0.1 to 0.9 in increments of 0.1.
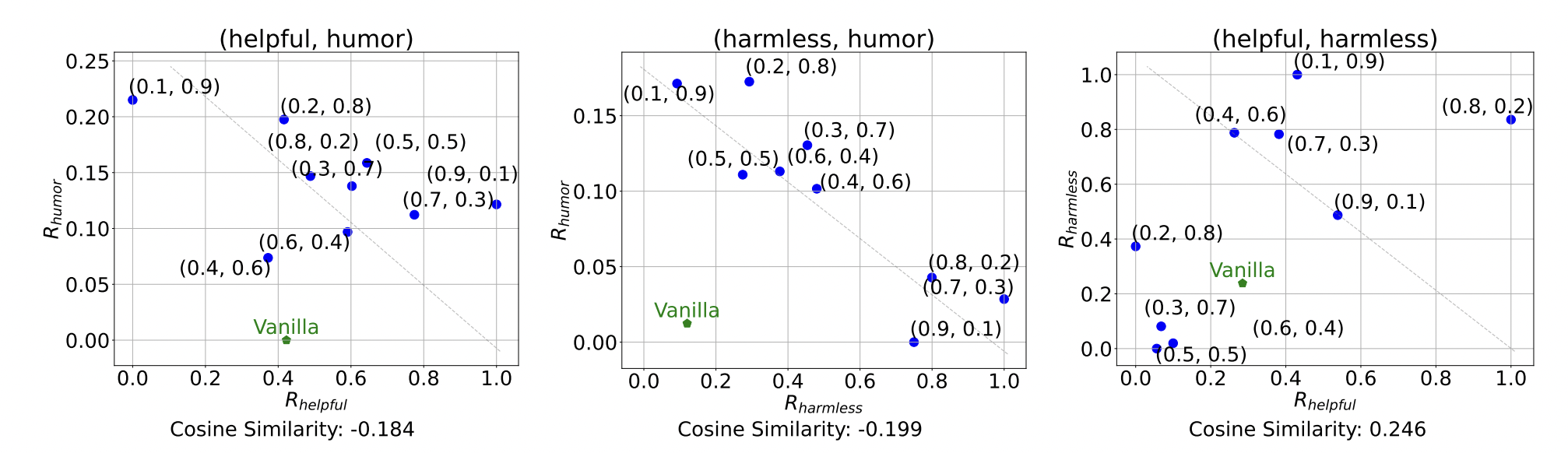
The result above shows that for uncorrelated preferences, (helpful, harmless) and (harmless, humor), AlignEZ successfully grant fine-grained control, as shown by the rewards that closely tracks the weight pairs ($\alpha$ and (1-$\alpha$)), showing precise tuning capabilities. Steering between correlated preference pair (helpful, harmless), however, shows limited effect. When we attempt to increase one while decreasing the other, their effects tend to counteract each other, resulting in minimal net change in model behavior.
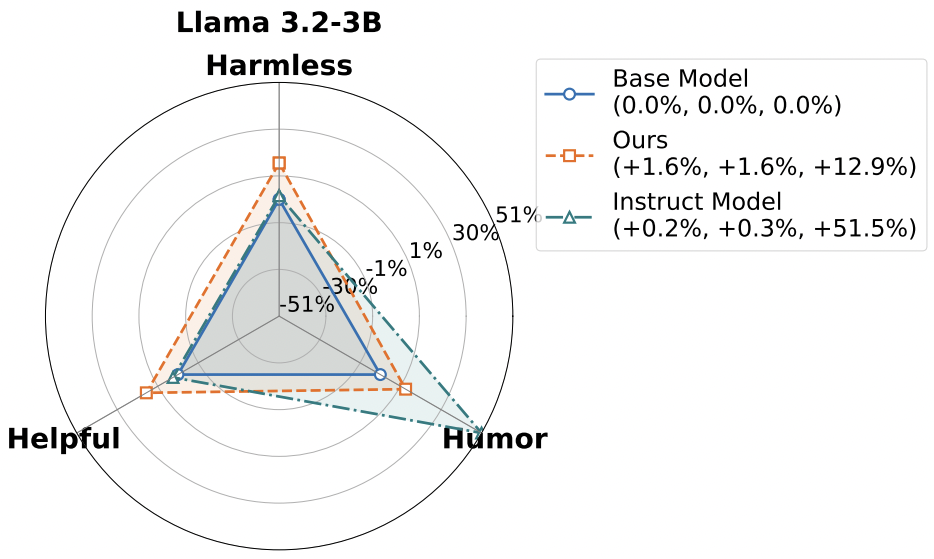
On steering across three preference axes at once, we can see that AlignEZ can simultaneously increase the desired preferences–even outperforming RLHF-ed model prompted to generate these characteristics on the harmless and helpful axes.
Result 3: Expediting More Expensive Algorithms
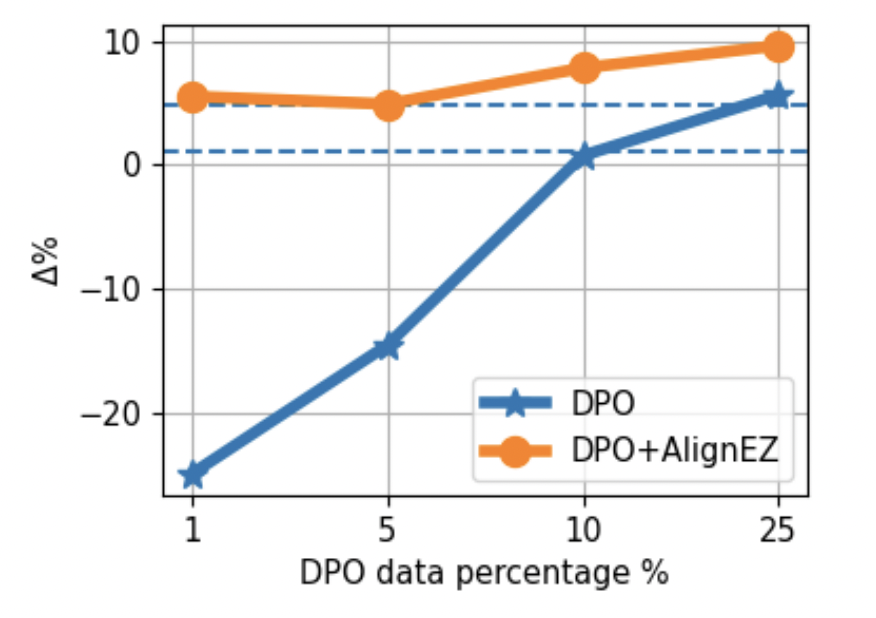
Wait, there’s more? yes! We also show that AlignEZ is compatible with classic, more expensive alignment techniques–even giving them significant boost. We show above that AlignEZ is able to lift the performance of a model trained with only 1% of the data to reach the performance of that trained on 25% of the data.

Result 4: (PoC) Improving Powerful Reasoning Models
With this set of results showing AlignEZ’s efficacy on alignment tasks, given its cost efficient and practical nature, we are excited about the possibility to extend it to more challenging tasks– ones that requires specialized knowledge such as mathematical reasoning and code intelligence. As a first step in this direction, we perform a proof of concept experiment, applying AlignEZ on multi-step mathematical reasoning benchmarks.
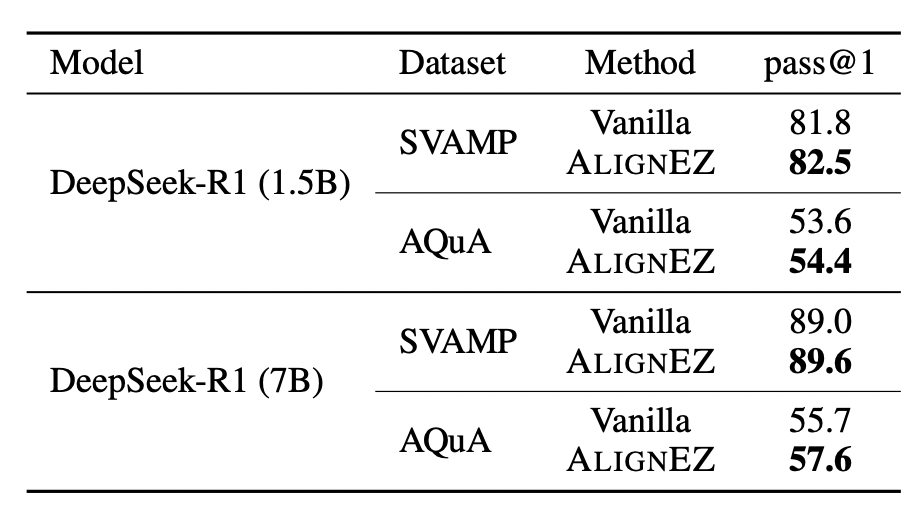
Surprisingly, even when starting from a strong reasoning model, vanilla AlignEZ provides improvements! We attribute these gains to the identified subspace, which appears to strengthen the model’s tendency toward step-by-step reasoning while suppressing shortcuts to direct answers.
Concluding Thoughts and What’s Next?
AlignEZ represents a paradigm shift in how we approach LLM alignment. By leveraging self-generated preference data and targeted embedding editing, we’ve demonstrated that effective alignment doesn’t require massive datasets or expensive fine-tuning cycles. Our approach offers several key advantages:
Resource Efficiency: AlignEZ works at inference time with minimal computational overhead, making it accessible to researchers and developers with limited resources.
Versatility: From single-objective alignment to complex multi-preference scenarios, AlignEZ provides flexible control without sacrificing performance.
Compatibility: As shown in our DPO experiments, AlignEZ can complement existing alignment techniques, accelerating their effectiveness even with limited training data.
No Preference Bottleneck: By generating its own preference data, AlignEZ removes one of the most significant bottlenecks in the alignment pipeline.
Our promising results open several exciting avenues for future research. Most obvious next direction to explore is domain-specific alignment– extending our proof-of-concept reasoning experiments, we plan to investigate how AlignEZ can enhance performance in specialized domains like medical advice, legal reasoning, and scientific research.
📜🔥: Check out our paper! https://arxiv.org/abs/2406.03642
💻 : Code coming soon! Stay tuned for our GitHub repository.