Tabby: Tabular Data Synthesis With Large Language Models
Published:
Authors: Sonia Cromp
While impressive examples of AI-generated art and dialogue have captured the public’s attention in recent years, one of the most fundamental data formats–tabular data–still lacks specialized, high-performing models. Tables are ubiquitous in modern life, but are not modeled well by off-the-shelf models intended for other datatypes. Given the central role of tabular data in everything from global economic forecasts and astronomical observations to classroom gradebooks and household budgets, the lack of deep learning methods tailored for tables is quite surprising. To address the table synthesis gap, we introduce Tabby: a foundation model designed specifically for tabular data. Tabby introduces the inductive biases necessary to represent tabular data into a pre-trained large language model, avoiding the costly process of training a foundation model from scratch. Read on to discover how Tabby generates synthetic data that is nearly indistinguishable from real-world datasets!
![]()
Why is synthetic tabular data useful?
The ability to generate high-quality synthetic tabular data has far-reaching applications across numerous domains. One of the most compelling use cases is medical research, where strict privacy regulations prevent real patient datasets from being widely shared. These restrictions, while essential for protecting sensitive information, can slow down collaboration and innovation. If researchers could instead generate and share synthetic patient datasets that mimic real data while ensuring privacy, medical discoveries could be accelerated on a global scale—enabling scientists to uncover insights without compromising patient confidentiality.
Table synthesis also plays crucial roles in data augmentation and missing value imputation. In many real-world scenarios, such as observations of rare weather events, collecting large, high-quality datasets is expensive or impractical (feel free to check out my current work at NASA on this exact topic, for atypically powerful and destructive hurricanes). Additionally, many datasets suffer from incomplete records, and advanced synthesis techniques can be used to intelligently fill in missing values, preserving the integrity and usability of the data. For example, missing data is a common challenge in air traffic control when analyzing flight patterns and schedules. Reliable tabular missing value imputation methods would allow aviation authorities to reconstruct missing flight paths, estimate delay probabilities, and optimize air traffic flow—even when real-time data is incomplete.
How Tabby works
Tabby introduces a set of architectural modifications that can be applied to any transformer-based language model (LM), enabling it to generate high-fidelity synthetic tabular data. At its core, Tabby incorporates Gated Mixture-of-Experts (MoE) layers with column-specific parameter sets, allowing the model to better represent relationships between different table columns. These modifications introduce the necessary inductive biases that help the LM model structured tabular data rather than free-form text.
The figure below compares a Tabby model to a standard, non-Tabby “base” LLM, when intended for use with a dataset that has V columns:
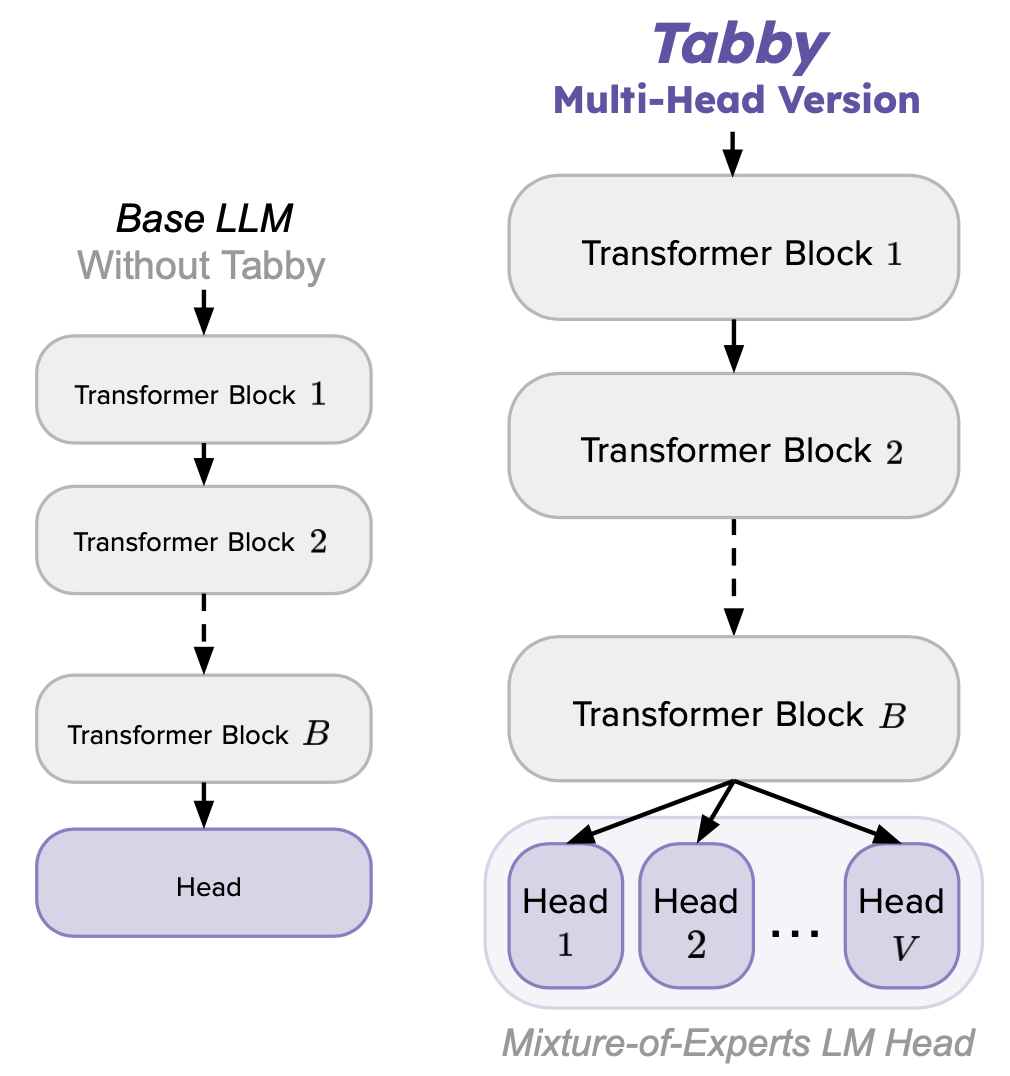
Despite these significant architectural changes, Tabby’s fine-tuning process remains straightforward—closely mirroring the pre-existing approaches for adapting LMs to tabular data. Moreover, Tabby is designed to retain and leverage the knowledge gained during the large-scale text pre-training phase, allowing for faster and more efficient adaptation to structured datasets.
Beyond Tabby itself, we also introduce Plain—a lightweight yet powerful training method for fine-tuning LMs (both Tabby and non-Tabby) on tabular data. Plain consistently improves the quality of synthetic data generation, regardless of the underlying LM. If you’re curious about how it works, check out our paper for the full details!
Evaluations: Tabby synthetic data reaches parity with non-synthetic data!
To assess Tabby’s performance, we follow standard benchmarks for tabular data synthesis, using a diverse set of datasets and the widely-accepted Machine Learning Efficacy (MLE) metric to measure data quality.
Datasets: We train Tabby models on six datasets spanning various domains and sizes:
| Name | # Rows | # Columns | Domain |
|---|---|---|---|
| Diabetes | 576 | 9 | Medical |
| Travel | 715 | 7 | Business |
| Adult | 36631 | 15 | Census |
| Abalone | 3132 | 9 | Biology |
| Rainfall | 12566 | 4 | Weather |
| House | 15480 | 9 | Geographical |
Metrics: MLE measures how well synthetic data preserves real-world patterns by comparing the performance of machine learning models trained on synthetic vs. real data. The closer the synthetic data’s MLE score is to the real data’s, the higher the fidelity of the synthetic dataset.
Results
In the table below, the first row represents the MLE score of real (non-synthetic) data. Any synthetic method that matches or surpasses this score is considered to have reached parity with real data.
Tabby achieves parity with real data on three out of six datasets (Diabetes, Travel, and Adult). Additionally, Tabby outperforms the prior best LLM-based tabular synthesis method on all six datasets.
| Name | Diabetes | Travel | Adult | Abalone | Rainfall | House |
|---|---|---|---|---|---|---|
| Upper Bound | 0.73 | 0.87 | 0.85 | 0.45 | 0.54 | 0.61 |
| Our Best Tabby Model | 0.74 ✅ | 0.88 ✅ | 0.85 ✅ | 0.43 | 0.49 | 0.60 |
| Prior best LM approach | 0.72 | 0.87 | 0.83 | 0.40 | 0.05 | 0.55 |
✅: Parity with real data!
Extensions
One of the most exciting discoveries in our work is that Tabby is not limited to tabular data. Unlike previous tabular synthesis models, Tabby successfully adapts to other structured data formats too, such as nested JSON records.
Why does this matter?
Most prior tabular synthesis methods struggle when faced with hierarchical or nested structures, which are common in web data, API responses, and metadata-rich datasets. Tabby’s architecture enables it to capture these structures effectively, opening up new possibilities for structured data generation.
We’re excited to explore this direction further and believe Tabby could be a foundation for generating a much broader class of structured synthetic data beyond just tables.
Takeaways
Tabby is a highly promising and easy-to-use approach for generating realistic synthetic tabular data. By leveraging Mixture-of-Experts (MoE) layers and the Plain training process, Tabby achieves parity with real data while outperforming previous tabular synthesis methods.
In our paper, we dive deeper into:
✅ The technical details behind Tabby’s architecture
✅ The Plain training process, which boosts data quality across different LLMs
✅ Extensive evaluations and comparisons against prior methods
For a deeper look, check out our paper or code. Feel free to reach out at cromp@wisc.edu—I’d love to hear your thoughts!