OTTER: Effortless Label Distribution Adaptation of Zero-shot Models
Published:
Authors: Changho Shin
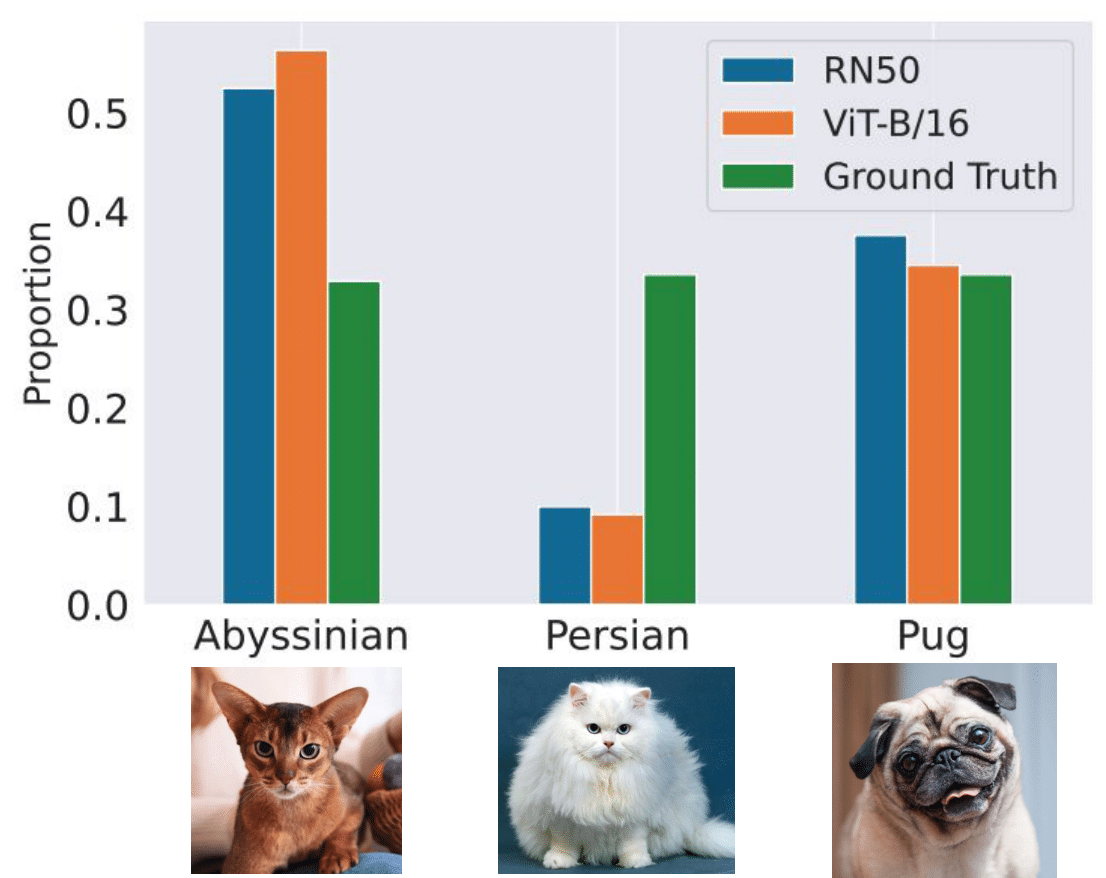
Zero-shot models are impressive—they can classify images or texts they’ve never seen before. However, these models often inherit biases from their massive pretraining datasets. If a model is predominantly exposed to certain labels during training, it may overpredict those labels when deployed in new tasks. OTTER (Optimal TransporT adaptER) addresses this challenge by correcting label bias at inference time without requiring extra training data.
In our recent work, we introduce OTTER, a lightweight method that rebalances the predictions of a pretrained model to better align with the label distribution of the downstream task. The key insight is to leverage optimal transport—a mathematical framework for matching probability distributions—to adjust the model’s output.
The Core Idea: Classification = Transporting Mass from the Input Space to the Label Space
OTTER reinterprets classification as the problem of transporting probability mass from the input space to the label space. In a traditional zero-shot classifier, given a set of \(n\) data points \(\{x_1, x_2, \dots, x_n\}\), the model outputs scores \(s_\theta(x_i, j)\) for each class \(j \in \{1, \dots, K\}\). Typically, we assign each data point the label corresponding to the highest score (i.e. \(\hat{y}_i = \arg\max_{j} s_\theta(x_i, j)\)).
OTTER, however, views these scores as indicating how much “mass” should ideally be transported from each data point \(x_i\) to a class \(j\). We first represent the empirical distribution of inputs as
\[\mu = \frac{1}{n} \sum_{i=1}^{n} \delta_{x_i},\]and we prescribe a target label distribution
\[\nu = (p_1, p_2, \dots, p_K),\]with \(\sum_{j=1}^{K} p_j = 1\). The goal is to reassign the mass from the input points to the classes so that the overall distribution of predicted labels matches \(\nu\).
This is achieved by formulating an optimal transport problem. We define a cost matrix \(C\) where each element is given by
\[C_{ij} = -\log s_\theta(x_i, j).\]This cost function naturally penalizes lower prediction scores, so moving mass to classes with higher scores incurs a lower cost. Then, OTTER solves for a transport plan \(\pi\) via
\[\pi = \arg\min_{\gamma \in \Pi(\mu, \nu)} \langle \gamma, C \rangle,\]where \(\Pi(\mu, \nu)\) denotes the set of all joint distributions whose marginals are \(\mu\) and \(\nu\). In other words, the plan \(\pi\) determines how to reassign the input mass such that exactly \(n \cdot p_j\) points are assigned to class \(j\).
By computing the optimal \(\pi\) and then taking
\(\hat{y}_i = \arg\max_{j} \pi_{ij},\) OTTER produces modified predictions that not only reflect the model’s confidence (through the cost structure) but also enforce the desired label distribution. When the target distribution \(\nu\) is chosen to match the true downstream distribution, this procedure effectively corrects for the bias introduced during pretraining.
The theoretical results in the paper show that if the cost matrix were derived from the true posterior (i.e. \(-\log P(Y = j \mid x_i)\)), then the optimal transport solution would recover the Bayes-optimal classifier. Since the true target distribution is typically unknown, OTTER uses an estimated downstream label distribution to rebalance the predictions accordingly.
Theoretical Underpinnings
A key theoretical insight is that under mild conditions, OTTER recovers the Bayes-optimal classifier. Specifically, if the true target probabilities are \(P_t(Y = j \mid X = x_i)\), then OTTER’s predictions:
\(\hat{y}_i = \arg\max_{j \in [K]} \pi_{ij},\) will match the Bayes-optimal decisions:
\[f_t(x_i) = \arg\max_{j \in [K]} P_t(Y = j \mid X = x_i).\]Moreover, our analysis provides error bounds using perturbation theory—bounding the sensitivity of the transport plan with respect to deviations in both the cost matrix and the target distribution. This ensures that OTTER is robust in practical settings, even when the label distribution estimate is slightly noisy.
Experiment Results
We evaluated OTTER on a diverse set of image and text classification tasks, and our findings reveal several key benefits:
- Improved Zero-Shot Performance:
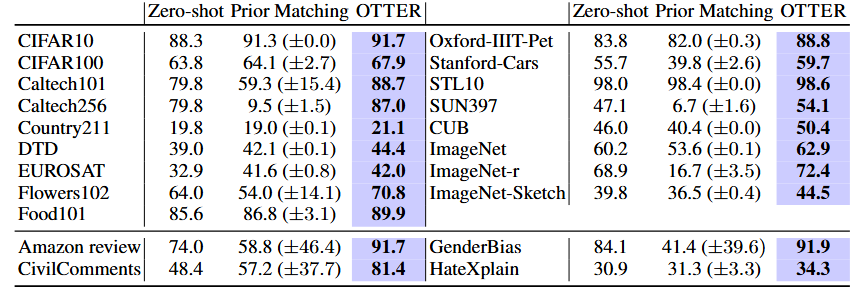
OTTER consistently boosts zero-shot classification accuracy, achieving an average improvement of about 4.8% on image tasks and up to 15.9% on text tasks across a variety of datasets.
- R-OTTER — Online Adaptation:
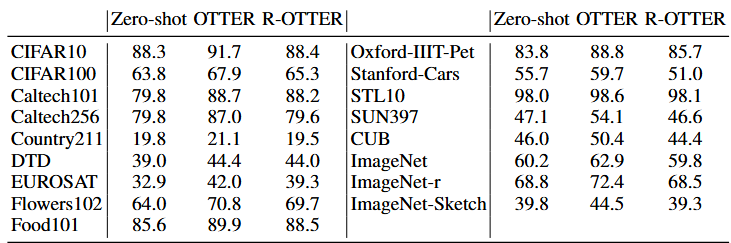
OTTER requires a potentially large batch size during prediction to function effectively. Our online variant, R-OTTER, overcomes this challenge by learning reweighting parameters from the model’s own pseudo-labels on a validation set, enabling real-time adjustments in dynamic environments without relying on additional labeled data.
- Mitigating Selection Bias:
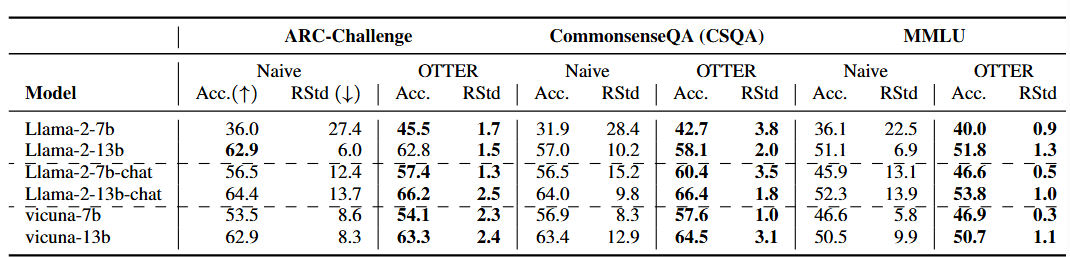
Selection bias in LLMs refers to their tendency to favor certain answer choices in multiple-choice questions (MCQs). OTTER effectively mitigates this bias by providing a simple yet effective mechanism to ensure a more balanced and representative distribution of model outputs.
Why It Matters for Practitioners
For practitioners deploying zero-shot models, OTTER offers:
- Ease of Use: A tuning-free, plug-and-play method that adjusts predictions on the fly.
- Robust Performance: Strong theoretical guarantees and consistent improvements across various datasets.
- Flexibility: Extensions like R-OTTER enable online adjustments and can incorporate label hierarchy information to further refine predictions.
Concluding Thoughts

OTTER offers a practical approach to mitigating label bias in zero-shot models, enhancing their reliability and adaptability in real-world applications. Check out our paper: https://arxiv.org/abs/2404.08461 and code on GitHub: https://github.com/SprocketLab/OTTER.
Thank you for reading!