Blog posts
2025
Re-Structuring CLIP's Language Capabilities
Vision-language models (VLM) like CLIP have transformed how we approach image classification. The performance of these models is heavily influenced by subtle choices such as pr...
Tabby: Tabular Data Synthesis With Large Language Models
While impressive examples of AI-generated art and dialogue have captured the public’s attention in recent years, one of the most fundamental data formats–tabular data–still lack...

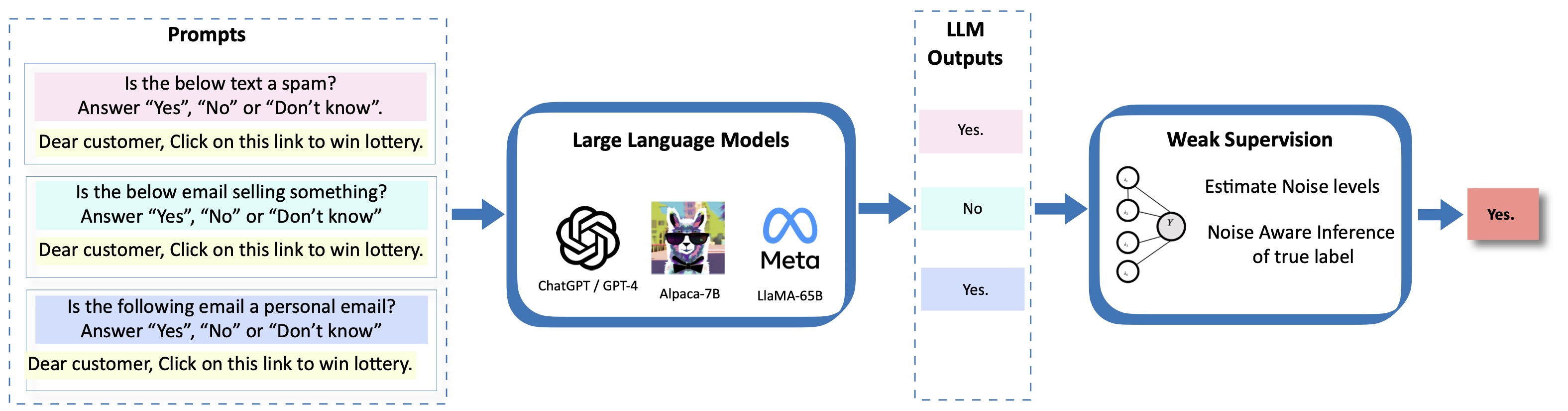
The ALCHEmist: Automated Labeling 500x CHEaper Than LLM Data Annotators
Large pretrained models like GPT-4, Gemini, and Claude 3 are fantastic at labeling data—-whether it’s spam detection in YouTube comments or classifying topics in medical documen...

Alignment, Simplified: Steering LLMs with Self-Generated Preferences
Efficient LLM alignment without the data and compute expense of traditional methods.

Weak-to-Strong Generalization Through a Data-Centric Lens
Exploring how overlap density drives weak-to-strong generalization and its applications in data source selection.

OTTER: Effortless Label Distribution Adaptation of Zero-shot Models
OTTER offers a tuning-free, inference-time label distribution adaptation of zero-shot models by leveraging optimal transport.
2023

RoboShot: Zero-Shot Robustification of Zero-Shot Models
Effortlessly robustify CLIP-based models to handle spurious currelations-- no xtra data, no xtra training!